本月份(2017年3月),IBM的Hyperledger Fabric文件出來了。這是另外一種Blockchain,稱為Permissioned Blockchain。與Bitcoin的Permissionless Blockchain不同之處在於,Bitcoin的Blockchain是大家都看的到,而Hyperledger Fabric,只有某些人,能看到部份Blockchain。這其實比較貼近大部份的實務應用。
在YouTube,有一個例子,說明Permissioned Blockchain的使用案例。
Building a blockchain for business with the Hyperledger Project
看完視頻之後,再去看Hyperledger Fabric的文件,會更有感覺。
Hyperledger Fabric documentation
-Count
2017年3月29日 星期三
2017年3月27日 星期一
如何對Bitcoin進行Consensus Attack攻擊?
本篇從安全的角度,探討Bitcoin的原理。研究一套系統,若沒有深入思考安全的問題,就談不上真正的了解。如果能對Consensus Attack解釋清楚,那麼對Bitcoin的架構,也差不多了解一半了。
下面的例子,取自於「Mastering Bitcoin」這本書。本來,書中只有文字說明,難懂,何況是英文。我花了一些時間研讀,搞懂之後,用自己的方式,用中文,並且圖文並茂,希望能說明清楚。

Mallory向Carol買一幅畫「The Great Fire」,並且雙方同意用Bitcoin交易。不過Mallory是一個不懷好意的買家,他想用Consensus Attack方式,騙取這幅畫。他要如何做到?
首先,由Mallory的錢包產生兩筆Transaction:tx1和tx2。tx1是用$25,000金額購買這幅畫,錢是給Carol。而tx2是惡意產生出來的Double Spending Transaction,$25,000錢是給Mallory自己。
我們知道,正常情況下,Bitcoin是不允許Double Spending Transaction存在的。因此Consensus Attack就是利用這一點來進行騙取。
Mallory將產生的tx1傳送給Carol,Carol檢查tx1,並且等10分鐘,讓tx1進入blockchain的最新Block,也就是這時tx1的confirmation次數為1。Carol認為這樣交易沒問題,拿到錢,就把這幅畫賣給Mallory。
其實,Mallory將tx1傳給Carol同時,愉愉將惡意的tx2傳給Paul。Paul是惡意的挖礦集團,手下控制Bitcoin世界51%以上的礦工。他們努力挖礦,10分鐘後,也產生新的包含tx2的Block。這個時候,Bitcoin世界就產生Blockchain分叉。
Paul為了搶得自己的那一條Blockchain,他叫手下的礦工,繼續挖礦。他大概有1半以上的機率,先挖到礦,因為他控制了Bitcoin世界51%以上的礦工。再過10分鐘後,如果是他挖到了,那麼他自己的那條Blockchain就變長了,於是他的Blockchain就將會變成主幹。
再經過10分鐘,會有新的Block進來。不管是Paul集團挖到的,還是別人挖到的。這個新的Block會加入Paul的Blockchain。為什麼?因為Paul的Blockchain最長。而較短的那一條Blockchain就會被丟棄,同時裡面的tx1也將會被丟棄。
大家會想,tx1從Block脫離後,為何不能回到Transaction Pool,等待加入下一個Block?我們知道Bitcoin不允許Double Spending Transaction出現。這個時候,tx2己經在blockchain而tx1被踢出去了,tx1反而成為Double Spending Transaction,所以它不會回到transaction pool,而是直接被終結掉。
最後的情況就是,tx1被終結了,只留tx2。於是Carol沒有拿到錢,可是畫已經被Mallory拿走了。
Carol如何預防這種情況?一般來說,大筆金額的交易,要被6個block壓住,才算妥當。所以Carol最好等1個小時,確認tx1被confirm 6次,才能把畫給Mallory。
中本聰論文,最後一段,有算出Consensus Attack的成功機率。個人認為,這是論文的精華之處,以後再為大家解釋一下。
-Count
下面的例子,取自於「Mastering Bitcoin」這本書。本來,書中只有文字說明,難懂,何況是英文。我花了一些時間研讀,搞懂之後,用自己的方式,用中文,並且圖文並茂,希望能說明清楚。

Mallory向Carol買一幅畫「The Great Fire」,並且雙方同意用Bitcoin交易。不過Mallory是一個不懷好意的買家,他想用Consensus Attack方式,騙取這幅畫。他要如何做到?
首先,由Mallory的錢包產生兩筆Transaction:tx1和tx2。tx1是用$25,000金額購買這幅畫,錢是給Carol。而tx2是惡意產生出來的Double Spending Transaction,$25,000錢是給Mallory自己。
我們知道,正常情況下,Bitcoin是不允許Double Spending Transaction存在的。因此Consensus Attack就是利用這一點來進行騙取。
Mallory將產生的tx1傳送給Carol,Carol檢查tx1,並且等10分鐘,讓tx1進入blockchain的最新Block,也就是這時tx1的confirmation次數為1。Carol認為這樣交易沒問題,拿到錢,就把這幅畫賣給Mallory。
其實,Mallory將tx1傳給Carol同時,愉愉將惡意的tx2傳給Paul。Paul是惡意的挖礦集團,手下控制Bitcoin世界51%以上的礦工。他們努力挖礦,10分鐘後,也產生新的包含tx2的Block。這個時候,Bitcoin世界就產生Blockchain分叉。
Paul為了搶得自己的那一條Blockchain,他叫手下的礦工,繼續挖礦。他大概有1半以上的機率,先挖到礦,因為他控制了Bitcoin世界51%以上的礦工。再過10分鐘後,如果是他挖到了,那麼他自己的那條Blockchain就變長了,於是他的Blockchain就將會變成主幹。
再經過10分鐘,會有新的Block進來。不管是Paul集團挖到的,還是別人挖到的。這個新的Block會加入Paul的Blockchain。為什麼?因為Paul的Blockchain最長。而較短的那一條Blockchain就會被丟棄,同時裡面的tx1也將會被丟棄。
大家會想,tx1從Block脫離後,為何不能回到Transaction Pool,等待加入下一個Block?我們知道Bitcoin不允許Double Spending Transaction出現。這個時候,tx2己經在blockchain而tx1被踢出去了,tx1反而成為Double Spending Transaction,所以它不會回到transaction pool,而是直接被終結掉。
最後的情況就是,tx1被終結了,只留tx2。於是Carol沒有拿到錢,可是畫已經被Mallory拿走了。
Carol如何預防這種情況?一般來說,大筆金額的交易,要被6個block壓住,才算妥當。所以Carol最好等1個小時,確認tx1被confirm 6次,才能把畫給Mallory。
中本聰論文,最後一段,有算出Consensus Attack的成功機率。個人認為,這是論文的精華之處,以後再為大家解釋一下。
-Count
2017年3月21日 星期二
Learning Rate在Neural Network的作用
今天,我為了下面這條公式,思索了一整天,然後回想起,學生時代,微積分以及線性代數的種種有趣的事情。這或許是在這把年紀,學習Neural Network的有趣之處吧!

此公式出自於「Make Your Own Neural Network」這本書。想不透Learning Rate在其中的作用?也搞不懂,新的weight,為何要靠這條公式調整?現在,我懂了。
感謝Apple Pencil,幫我畫出下面幾張圖,弄清了思路。此公式的目的是,不斷調整w的值,直到找到最小的E值為止。用下圖來表達,就很清楚了。

為何此公式可以找到最小的E值?我畫出下面這張表格。

它是靠斜率。斜率越大,w的調整幅度就越大,反之就愈小,非常直觀。大家應該有爬過山,下山時,是不是遇到陡坡,跨的步伐就變大,到了平地,步伐就變小。這就是表格第2行想要表達的意思。
可以試一下矇眼下山。一開始遇到的坡,斜率是3,感覺步伐變大,為3。接下來遇到斜率是1的坡,步伐就變成1。最後是斜率1/3的坡,步伐變小,為1/3。雙腳應該感覺應該接近平地了吧。
那麼,為何該公式要有Learning Rate呢?其作用在於,讓我們在下山的時候,不要走太快,除了會傷膝蓋,也會錯過一些風景。這就是表格第3行所要表達的意思。大家自己去看,我就不多做解釋了。
我要稱讚「Make Your Own Neural Network」這本書,淺顯易懂。但不能因為這樣,就隨便翻,以為自己讀完了,反而會忽略了一些值得花時間研究的東西,這是不是Learning Rate給我們的啟發呢?
-Count

此公式出自於「Make Your Own Neural Network」這本書。想不透Learning Rate在其中的作用?也搞不懂,新的weight,為何要靠這條公式調整?現在,我懂了。
感謝Apple Pencil,幫我畫出下面幾張圖,弄清了思路。此公式的目的是,不斷調整w的值,直到找到最小的E值為止。用下圖來表達,就很清楚了。

為何此公式可以找到最小的E值?我畫出下面這張表格。

它是靠斜率。斜率越大,w的調整幅度就越大,反之就愈小,非常直觀。大家應該有爬過山,下山時,是不是遇到陡坡,跨的步伐就變大,到了平地,步伐就變小。這就是表格第2行想要表達的意思。
可以試一下矇眼下山。一開始遇到的坡,斜率是3,感覺步伐變大,為3。接下來遇到斜率是1的坡,步伐就變成1。最後是斜率1/3的坡,步伐變小,為1/3。雙腳應該感覺應該接近平地了吧。
那麼,為何該公式要有Learning Rate呢?其作用在於,讓我們在下山的時候,不要走太快,除了會傷膝蓋,也會錯過一些風景。這就是表格第3行所要表達的意思。大家自己去看,我就不多做解釋了。
我要稱讚「Make Your Own Neural Network」這本書,淺顯易懂。但不能因為這樣,就隨便翻,以為自己讀完了,反而會忽略了一些值得花時間研究的東西,這是不是Learning Rate給我們的啟發呢?
-Count
2017年3月20日 星期一
如何產生Neural Network的Output?
這裡用3 Layer Neural Network為例,每一層都有3個節點,第3層節點的Output的值,可以用下面的公式算出來:
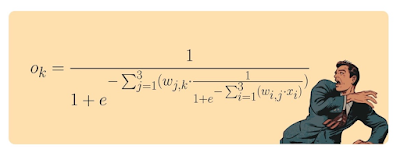
這張圖,出自於「Make Your Own Neural Network」這本書,作者可能想用這道公式,嚇唬大家,至少我被唬到了。我怪這些搞數學的,喜歡把公式寫的又臭又長,拿來唬人有用。但是對於想實作Neural Network的程序員來說,就頭大了。因為要把這種數學公式,翻譯成程式,腦袋要轉好幾個彎。
我常常抱怨,程序員的命不好,除了要翻譯各式各樣的Computer Language,還要看懂數學家寫的數學公式。相對而言,數學家就比較好命了,只要面對數學公式就可以,這一段只是我個人的看法。
國中時,我聽某位數學老師說過,公式,只是為了計算方便。
職場上的我說:Coding Standard,是為了寫程式方便。
最近的我說:遵循Coding Standard的數學公式,是為了方便程式員理解。
今天,我給大家一句話:「數學家,發明公式;程序員,撰寫程式」
這兩種人,各司其職,各有自己的飯碗要顧。
有些數學公式,會以程式的形式出現。喜歡賣弄程式技巧的人,就像這道數學公式一樣,只用一行把程式寫出來。數學公式這樣寫,可能是為了數學家獨特的審美觀,我不是數學家,不便評論。可是,若程序員,複雜的程式一行搞定,那是給接手的人麻煩。
抱怨完了,開始介紹如何實作初步的Neural Network。
一般程序員,大不了就按照這個數學公式,採用裡面的符號,直接寫出程式,這樣很快就交差了事。可是比較有理想的程序員,會想到以後的擴充性,如:3層變成4層。如果程式直接採用裡面的符號,想必將來變成4層,程式就會變得一團糟。避免這種情況發生,就要將Coding Standard的觀念,套用在數學公式上,亦即,拆解並改寫數學公式,使用漂亮可擴充的符號。這件事情,必須由程序員作的,不能期望數學家。程序員在解釋數學公式的同時,也要保留數學公式的原貌,算是對數學家的一種尊重。
還是回歸正題吧。
下圖是3x3 Neural Network,將符號重新命名,以方便將來的實作。有3層,分別是L1, L2, L3。不採用Input Layer, Hidden Layer, Output Layer,而採用編號的方式,是為了方便理解,及將來程式擴充方便。I代表Input的值,O代表Output的值。i, j, k, 就是我們寫程式時,會用到的迴圈變數。用i代表L1的某個節點、j代表L2的某個節點,k代表L3的某個節點。那麼,將來有4層時,要用什麼符號代表L4的節點呢?這個問題先打住。寫程式,先從簡單的開始,等到有一個樣子出現時,再重新定義符號(Refactoring),以方便擴充性。

基本符號定義好了之後,就開始Neural Network是如何運作。我們知道,L1不做任何運算,L2和L3會對權值加總後,做sigmoid運算。

至此,我們用習慣的符號,將Neural Network的程式,寫出來了。接下來,考慮擴充性。寫成Matrix是不錯的方法。對Neural Network有基本觀念的人,知道這些運算,可以用Matrix表示:

這個時候,想買弄數學技巧的程序員,可以寫成下面的式子,這和一開始的數學公式很像,但它是以Matrix形式表達。雖然我覺得,這似乎不是標準的數學公式,但大家應該能看的懂吧。

最後,開始做符號的Refactoring。我們把X, SX, Y這些難以通用的符號換掉,採用I, O, W並且給它們的下標一個編號,代表第幾層。

這樣一來,數學公式,經過這翻更改之後,就算交給資淺的程序員,程式應該很快就可以寫出來吧?而且,也適用於TensorFlow,這個以後再說明。
-Count

這張圖,出自於「Make Your Own Neural Network」這本書,作者可能想用這道公式,嚇唬大家,至少我被唬到了。我怪這些搞數學的,喜歡把公式寫的又臭又長,拿來唬人有用。但是對於想實作Neural Network的程序員來說,就頭大了。因為要把這種數學公式,翻譯成程式,腦袋要轉好幾個彎。
我常常抱怨,程序員的命不好,除了要翻譯各式各樣的Computer Language,還要看懂數學家寫的數學公式。相對而言,數學家就比較好命了,只要面對數學公式就可以,這一段只是我個人的看法。
國中時,我聽某位數學老師說過,公式,只是為了計算方便。
職場上的我說:Coding Standard,是為了寫程式方便。
最近的我說:遵循Coding Standard的數學公式,是為了方便程式員理解。
今天,我給大家一句話:「數學家,發明公式;程序員,撰寫程式」
這兩種人,各司其職,各有自己的飯碗要顧。
有些數學公式,會以程式的形式出現。喜歡賣弄程式技巧的人,就像這道數學公式一樣,只用一行把程式寫出來。數學公式這樣寫,可能是為了數學家獨特的審美觀,我不是數學家,不便評論。可是,若程序員,複雜的程式一行搞定,那是給接手的人麻煩。
抱怨完了,開始介紹如何實作初步的Neural Network。
一般程序員,大不了就按照這個數學公式,採用裡面的符號,直接寫出程式,這樣很快就交差了事。可是比較有理想的程序員,會想到以後的擴充性,如:3層變成4層。如果程式直接採用裡面的符號,想必將來變成4層,程式就會變得一團糟。避免這種情況發生,就要將Coding Standard的觀念,套用在數學公式上,亦即,拆解並改寫數學公式,使用漂亮可擴充的符號。這件事情,必須由程序員作的,不能期望數學家。程序員在解釋數學公式的同時,也要保留數學公式的原貌,算是對數學家的一種尊重。
還是回歸正題吧。
下圖是3x3 Neural Network,將符號重新命名,以方便將來的實作。有3層,分別是L1, L2, L3。不採用Input Layer, Hidden Layer, Output Layer,而採用編號的方式,是為了方便理解,及將來程式擴充方便。I代表Input的值,O代表Output的值。i, j, k, 就是我們寫程式時,會用到的迴圈變數。用i代表L1的某個節點、j代表L2的某個節點,k代表L3的某個節點。那麼,將來有4層時,要用什麼符號代表L4的節點呢?這個問題先打住。寫程式,先從簡單的開始,等到有一個樣子出現時,再重新定義符號(Refactoring),以方便擴充性。

基本符號定義好了之後,就開始Neural Network是如何運作。我們知道,L1不做任何運算,L2和L3會對權值加總後,做sigmoid運算。

至此,我們用習慣的符號,將Neural Network的程式,寫出來了。接下來,考慮擴充性。寫成Matrix是不錯的方法。對Neural Network有基本觀念的人,知道這些運算,可以用Matrix表示:

這個時候,想買弄數學技巧的程序員,可以寫成下面的式子,這和一開始的數學公式很像,但它是以Matrix形式表達。雖然我覺得,這似乎不是標準的數學公式,但大家應該能看的懂吧。

最後,開始做符號的Refactoring。我們把X, SX, Y這些難以通用的符號換掉,採用I, O, W並且給它們的下標一個編號,代表第幾層。

這樣一來,數學公式,經過這翻更改之後,就算交給資淺的程序員,程式應該很快就可以寫出來吧?而且,也適用於TensorFlow,這個以後再說明。
-Count
2017年3月18日 星期六
Neural Network如何選用Sigmoid Function?
為了搭上AI的熱潮,開始寫一些相關文章,因為除了本人對它感興趣之外,也是最近非碰不可,不然就落伍了。Neural Network為何不用Step Function?大家可以自己找書來看。有一本書,「Make Your Own Neural Network」,有不錯的解釋。
本篇要探討的是,如何挑選一個可以取代Step Function的Sigmoid Function?這個問題,似乎是有點吹毛求疵,因為專家說,使用Sigmoid Function就沒錯了,聽專家的話,就對了。但我就是好奇,發明Neural Network的人是如何知道要用Sigmoid Function?應該不是憑空想出來的。
南宋哲學家,朱熹,提倡「格物致知」。我的解釋是,光聽專家的意見,或看書是不夠的,要用批判的心態去質疑。因為透過書或專家的解釋,那是二手的,有時候自己會以為書上寫的很清楚,會容易誤以為自己真的了解,嚴重者是獲得錯誤的知識,而產生錯誤的認知,可能會影響一輩子。所以,沒有去做一些「格物致知」功夫,書讀再多也是枉然。
講了這麼多,無非是想大家知道,本人不是沒事找渣,是為了「格物致知」。古代人「格」事物,能用的工具有限。現代人,可以用的工具就很多了。
剛開始去理解Sigmoid Function時,發現有兩個部份要「格」,公式和曲線圖。更進一步「格」,發現,公式不是目的,曲線圖才是目的。發明Neural Network的人,認為Step Function太陡了,需要一個平滑的曲線。如果我是發明Neural Network的人,憑自己的才智,無法馬上想到公式,而是先畫出一個心目中希望出現的曲線出來,然後再從這個曲線,找出能夠套用它的公式。可能不只一個公式,但盡量找到一個簡單的公式給大家或電腦用。
當然,我看過這個公式長什麼樣子,已經先知道答案了,所以從曲線「格」出公式,有作幣的嫌疑。但從「格」的過程,可以幫助我了解公式的原理,而不光是死記公式。
首先,把想要的曲線畫出來。希望的曲線是,保留Step Function的大部份特性,亦即x<<0時y=0、x=0時y=1/2、x>>0時y=1,但是要平滑。

然後就用下面的表格,把公式「格」出來。

先把 y = 0, 1/2, 1 放到表格的第一列,從這一列開始「格」公式。經過步驟1和2之後,產生表格的第3列,公式就快浮出水面了。於是這個問題,就簡化為,找格∞, 1, 0的公式,這就是經由步驟3後,產生表格的第4列。
印象中,很像之前學過的y = e^x,不過它的值倒過來,是0, 1, ∞。這就是經由步驟4,產生的第5列。而符合第5列的公式,就是e^x,這就是步驟5的結果。為何選e?不選其它的數字?這可能是e有些有趣的特性,導致大部份的數學家喜歡使用它來建立公式。
接下來,我們就往表格的上方走。經由步驟6,產生e^(-x),因為它是左右對稱的。最後是步驟7,將e^(-x)放進右下角那塊存放∞, 1, 0值的區域。於是,Sigmoid Function就被「格」出來了。
在「Make Your Own Neural Network」這本書提到,Step Function有Threshold,可是Sigmoid Function似乎沒有考慮到Threshold?這是我的疑點,下次再去「格」它。
本篇,是我去「格」Sigmoid Function的心路歷程。當然,講給大家聽,就變成「二手」的。其中一個目的,是希望讓大家知道,如何「格物致之」。當然,大家還是要去質疑,其中的對錯。
-Count
本篇要探討的是,如何挑選一個可以取代Step Function的Sigmoid Function?這個問題,似乎是有點吹毛求疵,因為專家說,使用Sigmoid Function就沒錯了,聽專家的話,就對了。但我就是好奇,發明Neural Network的人是如何知道要用Sigmoid Function?應該不是憑空想出來的。
南宋哲學家,朱熹,提倡「格物致知」。我的解釋是,光聽專家的意見,或看書是不夠的,要用批判的心態去質疑。因為透過書或專家的解釋,那是二手的,有時候自己會以為書上寫的很清楚,會容易誤以為自己真的了解,嚴重者是獲得錯誤的知識,而產生錯誤的認知,可能會影響一輩子。所以,沒有去做一些「格物致知」功夫,書讀再多也是枉然。
講了這麼多,無非是想大家知道,本人不是沒事找渣,是為了「格物致知」。古代人「格」事物,能用的工具有限。現代人,可以用的工具就很多了。
剛開始去理解Sigmoid Function時,發現有兩個部份要「格」,公式和曲線圖。更進一步「格」,發現,公式不是目的,曲線圖才是目的。發明Neural Network的人,認為Step Function太陡了,需要一個平滑的曲線。如果我是發明Neural Network的人,憑自己的才智,無法馬上想到公式,而是先畫出一個心目中希望出現的曲線出來,然後再從這個曲線,找出能夠套用它的公式。可能不只一個公式,但盡量找到一個簡單的公式給大家或電腦用。
當然,我看過這個公式長什麼樣子,已經先知道答案了,所以從曲線「格」出公式,有作幣的嫌疑。但從「格」的過程,可以幫助我了解公式的原理,而不光是死記公式。
首先,把想要的曲線畫出來。希望的曲線是,保留Step Function的大部份特性,亦即x<<0時y=0、x=0時y=1/2、x>>0時y=1,但是要平滑。

然後就用下面的表格,把公式「格」出來。

先把 y = 0, 1/2, 1 放到表格的第一列,從這一列開始「格」公式。經過步驟1和2之後,產生表格的第3列,公式就快浮出水面了。於是這個問題,就簡化為,找格∞, 1, 0的公式,這就是經由步驟3後,產生表格的第4列。
印象中,很像之前學過的y = e^x,不過它的值倒過來,是0, 1, ∞。這就是經由步驟4,產生的第5列。而符合第5列的公式,就是e^x,這就是步驟5的結果。為何選e?不選其它的數字?這可能是e有些有趣的特性,導致大部份的數學家喜歡使用它來建立公式。
接下來,我們就往表格的上方走。經由步驟6,產生e^(-x),因為它是左右對稱的。最後是步驟7,將e^(-x)放進右下角那塊存放∞, 1, 0值的區域。於是,Sigmoid Function就被「格」出來了。
在「Make Your Own Neural Network」這本書提到,Step Function有Threshold,可是Sigmoid Function似乎沒有考慮到Threshold?這是我的疑點,下次再去「格」它。
本篇,是我去「格」Sigmoid Function的心路歷程。當然,講給大家聽,就變成「二手」的。其中一個目的,是希望讓大家知道,如何「格物致之」。當然,大家還是要去質疑,其中的對錯。
-Count
Transaction的後半生
前篇講到Transaction的前半生,從Create、Broadcast、到Propagate。真正精彩的是牠的後半生,以及牠的「生後」所發生的事情。
Transaction一旦進入Transaction Pool,就進入了牠的後半生,等待和Block結合。而Block會和Blockchain結合。在Transaction在Blockchain的日子裡,剛始的的狀態是不穩定的,有可能Block會離開Blockchain,Block一離開,就崩解,裡面的Transaction都解放出來。Block被埋在Blockchain愈深,Block就愈穩定,Transaction就愈難離開。這時候的Transaction可視為「壽終正寢」並且「蓋棺論定」了。
細節,我為大家一一道來。

Transaction,tx1,牠的前半生,像病毒一樣散播給全世界的Node。Node會去Verify tx1,若Node具有挖礦能力,稱為Miner,Verify通過,會把牠安置在Transaction Pool。這時tx1的狀態是Verified,開始進入牠的後半生。
Miner收集到足夠多的Transaction後,就開始建立一個Candidate Block,標記為Block 2,Miner按照優先順序,從Pool挑選到tx1,放到Block 2裡,開始對它挖礦。
我們把Block視為一道難解的問題,挖礦目的是去找到問題的答案。為了維持,全世界每10分鐘產生一個新的Block的節奏,該題目的難度是會被調整的。什麼是難解問題?如何挖礦?將在另一篇文章裡說明。
若Miner找到Block 2的解答,表示挖到礦,Miner將此Block 2放到Blockchain最上層的Block 1上面。這時候,tx1的狀態變成Confirmed。
這時候,在Blockchain裡面的tx1,還不算是穩定的。因為Miner還沒有將Block 2廣播出去,而且,其它的Miner也可能挖到礦。這種情況下,就會出現Blockchain的分叉。解決分叉的辦法,就是等新的Block出現,看它出現在那一個分叉,保留最長分叉的那一支Blockchain,短的那一支的Block就捨棄。所以,若Miner辛苦挖的Block 2不幸落入短的分叉,Block 2就會解體,裡面的Transaction,若還沒有被放在最新Blockchain裡,就會回到Transaction Pool。這時候的狀態,從Confirmed,變回Verified。
Blockchain的分叉,有時間,我再另擇文說明。
我們稱,Transaction有One Confirmation的意思是,牠現在在Blockchain裡面,並且埋在牠所屬的Block位於Blockchain的最上層。Two Confirmation的意思就是,被兩個Block埋,所屬的Block上面還有一個Block。
所以Confirmation的次數愈多,表示Transaction被Block埋的深度愈深,埋的愈深,出土或復活的機會就愈少,可以視為該Transaction「壽終正寢」了。
通常,大筆金額交易,要等6個Confirmation完成,亦即被6個Block埋,這就是我說的「蓋棺論定」的意思。也就是該Transaction的功過,己經被牢牢寫在Blockchain裡了。
-Count
Transaction一旦進入Transaction Pool,就進入了牠的後半生,等待和Block結合。而Block會和Blockchain結合。在Transaction在Blockchain的日子裡,剛始的的狀態是不穩定的,有可能Block會離開Blockchain,Block一離開,就崩解,裡面的Transaction都解放出來。Block被埋在Blockchain愈深,Block就愈穩定,Transaction就愈難離開。這時候的Transaction可視為「壽終正寢」並且「蓋棺論定」了。
細節,我為大家一一道來。

Transaction,tx1,牠的前半生,像病毒一樣散播給全世界的Node。Node會去Verify tx1,若Node具有挖礦能力,稱為Miner,Verify通過,會把牠安置在Transaction Pool。這時tx1的狀態是Verified,開始進入牠的後半生。
Miner收集到足夠多的Transaction後,就開始建立一個Candidate Block,標記為Block 2,Miner按照優先順序,從Pool挑選到tx1,放到Block 2裡,開始對它挖礦。
我們把Block視為一道難解的問題,挖礦目的是去找到問題的答案。為了維持,全世界每10分鐘產生一個新的Block的節奏,該題目的難度是會被調整的。什麼是難解問題?如何挖礦?將在另一篇文章裡說明。
若Miner找到Block 2的解答,表示挖到礦,Miner將此Block 2放到Blockchain最上層的Block 1上面。這時候,tx1的狀態變成Confirmed。
這時候,在Blockchain裡面的tx1,還不算是穩定的。因為Miner還沒有將Block 2廣播出去,而且,其它的Miner也可能挖到礦。這種情況下,就會出現Blockchain的分叉。解決分叉的辦法,就是等新的Block出現,看它出現在那一個分叉,保留最長分叉的那一支Blockchain,短的那一支的Block就捨棄。所以,若Miner辛苦挖的Block 2不幸落入短的分叉,Block 2就會解體,裡面的Transaction,若還沒有被放在最新Blockchain裡,就會回到Transaction Pool。這時候的狀態,從Confirmed,變回Verified。
Blockchain的分叉,有時間,我再另擇文說明。
我們稱,Transaction有One Confirmation的意思是,牠現在在Blockchain裡面,並且埋在牠所屬的Block位於Blockchain的最上層。Two Confirmation的意思就是,被兩個Block埋,所屬的Block上面還有一個Block。
所以Confirmation的次數愈多,表示Transaction被Block埋的深度愈深,埋的愈深,出土或復活的機會就愈少,可以視為該Transaction「壽終正寢」了。
通常,大筆金額交易,要等6個Confirmation完成,亦即被6個Block埋,這就是我說的「蓋棺論定」的意思。也就是該Transaction的功過,己經被牢牢寫在Blockchain裡了。
-Count
2017年3月17日 星期五
Transaction的前半生
要了解Blockchain,得先了解Transaction不可。因為Blockchain是死的,Transaction是活的,Blockchain是Transaction的墳墓,所以先了解Transaction,再了解Block,最後是Blockchain,按照這個順序,思路會比較清楚。
Transaction,字面上的意思就是交易,有牠存活的時間,我將牠分為「前半生」和「後半生」。從Transaction的誕生,到與Block結合之前,是牠的「前半生」。與Block結合時,就開始走向牠的「後半生」。牠有捨棄Block的機會。但若被另外一個Block壓住,離開的機會就變少了。被愈多Block壓住,就愈難離開。我們可以將牠視為被埋葬了,亦即「壽終正寢」並且「蓋棺論定」。
如下圖,Transaction的前半生,分三個階段:

Transaction,字面上的意思就是交易,有牠存活的時間,我將牠分為「前半生」和「後半生」。從Transaction的誕生,到與Block結合之前,是牠的「前半生」。與Block結合時,就開始走向牠的「後半生」。牠有捨棄Block的機會。但若被另外一個Block壓住,離開的機會就變少了。被愈多Block壓住,就愈難離開。我們可以將牠視為被埋葬了,亦即「壽終正寢」並且「蓋棺論定」。
如下圖,Transaction的前半生,分三個階段:
- Create
- Broadcast
- Propagate

Step 1 - Create
Transaction如何誕生?例如,Alice向Bob買一杯咖啡,想用Bitcoin交易,於是Alice開啟手機上Bitcoin Wallet App,去掃Bob POS上顯示該咖啡的QR Code,Wallet App就會生出一個Transaction。
Step 2 - Broadcast
接下來要告知全世界的Node,誕生了一個Transaction。首先,廣播(Broadcast)出去。通常Bob的POS會先收到Alice的Transaction,然後去驗證牠,驗證沒問題,Bob才會放心把咖啡遞給Alice。Transaction可以透過任何形式通道廣播,如:Wi-Fi、Bluetooth、NFC等,並且可以是Non Secure Channel,亦即通道不需要加密,這和一般信用卡交易不同。
Step 3 - Propagate
收到Transaction的Node,驗證沒問題,就開始繁殖(Propagate)牠,並且傳給其它3到4個Node。這裡為何強調「繁殖」,意思是,Node自己也要保留一份Transaction,挖礦用的。很快地,就像散播病毒一樣,全世界的Node都會收到Transaction。
Transaction的前半生,就說到這裡了。下一篇文章,會講牠的後半生、牠如何和Block結合、如何「壽終正寢」、以及怎樣才算是「蓋棺論定」。精彩的在後頭,Transaction的後半生。
-Count
2017年3月15日 星期三
Full Node和SPV Node如何驗證Transaction?
對於Full Node和SPV Node如何驗證Transaction?在閱讀完以下論文、書籍、網上資料後,我把這個問題整理出來,希望能解釋清楚,讓大家了解:
- Bitcoin: A Peer-to-Peer Electronic Cash System
- Mastering Bitcoin
- https://en.bitcoin.it/wiki/Thin_Client_Security
首先,我們要知道,Transaction的驗證,實際上有兩件事情要做。前篇文章有提:
- Transaction存在性檢查
- Transaction無重花(重覆花費)檢查
Full Node和SPV Node對這兩項檢查的策略不同,Full Node是走Height,SPV Node是走Depth。想必大家剛開始研究Bitcoin時,也常常搞不清楚什麼是Height,什麼是Depth?希望本文,對照下圖,能為大家撥雲見日:


Verify Transaction
- Full Node - Block Height Verification
- SPV Node - Block Depth Verification
Full Node - BHV (Block Height Verification)
Full Node就是有完整Blockchain的Node,所以檢查Transaction是否存在Block,就拿它與整個Blockchain搜尋一下就好了。
Transaction存在性檢查通過,並不保證該Transaction的Input不是重花,所以要進行這項檢查。方法有兩種:
方法一:如圖,我們要檢查的Transaction叫tx2,它己經被驗證是在Block 300000裡。於是Full Node就往之前的Block去找Transaction串列,如找到tx1的output是tx2的input,就表示tx2的確被花費了。為了確保tx2沒有被重花,還得往更前面的Block去找,直到Genesis Block為止。
方法二:從Blockchain建立UTXO Pool,也就是將所有未花費的transaction收集起來。其實一旦建立了UTXO Pool,也就驗證了所有Transaction沒有被重花。
SPV Node - BDV (Block Depth Verification)
這種方法,在中本聰論文提到。SPV Node只有Block Header,為了檢查Transaction是否存在某個Block,就去問Full Node,它會回傳Merkle Path給SPV Node,SPV Node用它來驗證該Transaction是否存在Block,此驗證方稱之為Merkle Path Proof。
一樣,Transaction存在性檢查通過,並不保證該Transaction的Input不被重花。SPV Node採用不同的方式,它是去看之後的Block有幾個。愈多,表示該Transaction所屬的Block被「埋」的愈深,用Depth表示Transaction被埋的深度。埋的愈深,表示該Transaction被Confirm的次數就愈多。一般來說,Transaction被6個Block埋,就夠了。這表示該Transaction在Blockchain裡面,是被大家核準通過的,而且沒有重花。
當然,BDV的嚴謹性,比不上BHV。因為SPV Node沒有全部的Transaction,無法做到BHV,BDV是退而求其次的方法。
-Count
Bitcoin Block 如何儲存 Merkle Tree?
中本聰在Bitcoin P2P Network的論文提到,Merkle Tree在SPV Client應用。我們知道,SPV Client不儲存所有的Transaction。當它要確認某個Transaction是否在Block裡,就去問Peer,Peer回傳Merkle Path,給SPV Client驗證就行了。
本篇提出一些問題給大家深入思考:
問題一:Maerkle Tree存在何處?
我們知道,Merkle Tree是一種Binary Hash Tree。它的用途和原理這裡就不多說了,不熟的,請大家自己上網找。為了本文講解方便,列出相關名詞。
Merkle Tree裡的Node分為兩類,Leaf Node與Non-Leaf Node,Non-Leaf Node裡面,還有一個惟一的Node叫Root Node,用來代表整個Merkle Tree。
Merkle Tree
簡單來說,每一個Transaction的Hash值存在Leaf Node,兩兩Leaf Node的Hash值存放在上一層的Node,直到Root Node,其值,就是用來代表Block所包含的所有Transaction。
那麼,Merkle Tree存在那裡?我一直以為是在Block,後來發現,其實Block只存Root Node,連Leaf Node都不存。除了Root Node之外,其它Node都是依照需要,當場計算出來的。我把Block和Transaction的關係,畫成下面這張圖:

從圖中,我們可以很清楚的知道,Block和Transaction都不存Merkle Tree,連Leaf Node都無,只有存在Block Header的Merkle Root,是用來驗證它所包含的Transactions完整性的最後一關。
Full Peer會儲存完整的Block:Block Size + Block Header + Transaction Counter + Transactions
SPV (Simplified Payment Verification) Client只存精簡的Block:Block Size + Block Header
Full Peer會儲存完整的Transaction,但也沒有Merkle Tree,甚至連Transaction Hash也沒有。
Transaction Input的Transaction Hash指的是關連到上一筆的Transaction,而非這一筆。
不管是Full Peer還是SPV Client,Transaction有兩項要檢查:
Full Peer和SPV Client對這兩項的檢查方式會有所不同,我將會寫另一篇文章探討。本文拿,SPV Client對Transaction做存在性檢查,做為一個例子,解釋Merkle Tree在這檢查的過程中,起了什麼樣的做用。
檢查Transaction是否真的在某個Block裡?我猜想的步驟如下:
這是因為,SPV Client無法確認Full Peer是否可信的?Bitcoin世界裡,Blockchain是惟一可信的,當然裡面的Block、Merkle Root、Transaction都是可信的。若待驗證的Transaction透過Merkle Path,可以接到可信的Merkle Root,那麼就可以驗證Transaction的存在性。
這種驗證Transaction存在性的方法,叫做Merkle Path Proof。再次強調,此法無法驗證Transaction的合法性,因為無法證明Transaction的Input不是重覆花費。
若Full Peer是惡意的,分析一下欺騙SPV Client的可能性如下:
Transaction不屬於Block1:
Full Peer可以騙SPV Client說:Transaction在Block1裡嗎?不行,因為很難做出一個假的Merkle Path,因為Merkle Root是一個不斷SHA256的值,要造假很困難。(題外話,若是SHA1就很容易造假了,因為Google最近發表,在可接受的時間內,產生相同的SHA1出來)
Transaction屬於Block1:
Full Peer可以騙SPV Client說:Transaction不在Block1嗎?可以。
以後再探討Bitcoin Network的安全問題。
問題二:除了Merkle Tree,還有什麼別的方法,可以用在SPV Client上?
為了建立Merkle Path,Full Peer要先從計算所有Leaf Node開始,再往上算出Non-Leaf Node,直到Root Node。為何不用較簡單的List資料結構?Hash所有Leaf Node,放到第1個Node?
List
用List,的確可以減輕Server的運算量,因為不用計算Node。但從Full Peer傳給SPV Client的資料量會變很多。原來傳給SPV Client的只要Merkle Path,只要Log(2, N),現在要N。想像1個Block有1024筆Transaction,其資料量就是 1024 x 36 (SHA256 size) = 36K bytes。如果傳的是Merkle Path,其資料量是 Log (2, 1024) x 36 = 360 bytes。
由此可見,Merkle Tree雖然會增加Full Peer計算Node的負擔,但不會很多。計算Leaf Node運算量會比較大,因為它是Hash兩個32 bytes的Leaf Node。而傳輸的資料會少很多。
再來看本文最初提的兩個問題:
結論:
-Count
本篇提出一些問題給大家深入思考:
- Merkle Tree存在何處?
- 除了Merkle Tree,還有什麼別的方法,可以用在SPV Client上?
問題一:Maerkle Tree存在何處?
我們知道,Merkle Tree是一種Binary Hash Tree。它的用途和原理這裡就不多說了,不熟的,請大家自己上網找。為了本文講解方便,列出相關名詞。
Merkle Tree裡的Node分為兩類,Leaf Node與Non-Leaf Node,Non-Leaf Node裡面,還有一個惟一的Node叫Root Node,用來代表整個Merkle Tree。
Merkle Tree
- Leaf Node
- Non-Leaf Node
- Root Node
簡單來說,每一個Transaction的Hash值存在Leaf Node,兩兩Leaf Node的Hash值存放在上一層的Node,直到Root Node,其值,就是用來代表Block所包含的所有Transaction。
那麼,Merkle Tree存在那裡?我一直以為是在Block,後來發現,其實Block只存Root Node,連Leaf Node都不存。除了Root Node之外,其它Node都是依照需要,當場計算出來的。我把Block和Transaction的關係,畫成下面這張圖:

Full Peer會儲存完整的Block:Block Size + Block Header + Transaction Counter + Transactions
SPV (Simplified Payment Verification) Client只存精簡的Block:Block Size + Block Header
Full Peer會儲存完整的Transaction,但也沒有Merkle Tree,甚至連Transaction Hash也沒有。
Transaction Input的Transaction Hash指的是關連到上一筆的Transaction,而非這一筆。
由此可知道,整個Blockchain、Block、與Transaction的資料結構,在設計上,是以儲存空間最小為考量,而非查詢方便為考量。這是因為Blockchain是大家共用的帳本,愈小,愈利於傳輸。
不管是Full Peer還是SPV Client,Transaction有兩項要檢查:
- Transaction存在性檢查 - 檢查Transaction是否真的存在Block裡
- Transaction沒有被重覆花費 - 檢查Transaction的Input不是重覆花費
Full Peer和SPV Client對這兩項的檢查方式會有所不同,我將會寫另一篇文章探討。本文拿,SPV Client對Transaction做存在性檢查,做為一個例子,解釋Merkle Tree在這檢查的過程中,起了什麼樣的做用。
檢查Transaction是否真的在某個Block裡?我猜想的步驟如下:
- SPV Client將這個問題包裝成 Q = (Transaction, Block Header)
- SPV Client將問題Q傳給Full Peer
- Full Peer拆解Q,若發現Transaction屬於Block,則建立Merkle Path
- Full Peer將Merkle Path傳給SPV Client
- 若SPV Client拿到Merkle Path,就表示Full Peer回答了Transaction是在Block裡。
- SPV Client也會對Merkle Path驗證Transaction是否真的存在Block,做二次驗證。
這是因為,SPV Client無法確認Full Peer是否可信的?Bitcoin世界裡,Blockchain是惟一可信的,當然裡面的Block、Merkle Root、Transaction都是可信的。若待驗證的Transaction透過Merkle Path,可以接到可信的Merkle Root,那麼就可以驗證Transaction的存在性。
這種驗證Transaction存在性的方法,叫做Merkle Path Proof。再次強調,此法無法驗證Transaction的合法性,因為無法證明Transaction的Input不是重覆花費。
若Full Peer是惡意的,分析一下欺騙SPV Client的可能性如下:
Transaction不屬於Block1:
Full Peer可以騙SPV Client說:Transaction在Block1裡嗎?不行,因為很難做出一個假的Merkle Path,因為Merkle Root是一個不斷SHA256的值,要造假很困難。(題外話,若是SHA1就很容易造假了,因為Google最近發表,在可接受的時間內,產生相同的SHA1出來)
Transaction屬於Block1:
Full Peer可以騙SPV Client說:Transaction不在Block1嗎?可以。
以後再探討Bitcoin Network的安全問題。
問題二:除了Merkle Tree,還有什麼別的方法,可以用在SPV Client上?
為了建立Merkle Path,Full Peer要先從計算所有Leaf Node開始,再往上算出Non-Leaf Node,直到Root Node。為何不用較簡單的List資料結構?Hash所有Leaf Node,放到第1個Node?
List
- Root Node
- Leaf Node
用List,的確可以減輕Server的運算量,因為不用計算Node。但從Full Peer傳給SPV Client的資料量會變很多。原來傳給SPV Client的只要Merkle Path,只要Log(2, N),現在要N。想像1個Block有1024筆Transaction,其資料量就是 1024 x 36 (SHA256 size) = 36K bytes。如果傳的是Merkle Path,其資料量是 Log (2, 1024) x 36 = 360 bytes。
由此可見,Merkle Tree雖然會增加Full Peer計算Node的負擔,但不會很多。計算Leaf Node運算量會比較大,因為它是Hash兩個32 bytes的Leaf Node。而傳輸的資料會少很多。
再來看本文最初提的兩個問題:
- Merkle Tree存在何處?
- 除了Merkle Tree,還有什麼別的方法,可以用在SPV Client上。
結論:
- Blockchain不存放Merkle Tree。
- 但在實作上,Full Peer可以建立一個方便查詢或建立Merkle Tree的Index。建Index的方法就有很多了。
- SPV Client採用Merkle Tree,這是運算量和資料傳輸量之間的折衷方案。
2017年3月11日 星期六
SPV Node如何用Bloom Filter詢問自己有多少錢?
Wallet (SPV Node)如何知道自己有多少錢?在上一篇文章,如何知道Bitcoin Wallet有多少錢,列出三種方法。
方法一:下載完整帳本(Blockchain)後自己從裡面去找
方法二:向Peer公開Wallet的所有訊息,Peer就回傳屬於該Wallet的UTXO
方法三:向Peer公開Wallet的部份訊息,Peer回傳可能屬於該Wallet的UTXO
用下圖說明,Wallet如何用Bloom Filter,去向Peer問,自己擁有多少錢。這裡,我們的前提條件是,Wallet被重啟後,只剩下Private Key,其它什麼都沒有。不用擔心,透過下面步驟,可以把錢找回來。

Wallet向Peer詢問,自己應該有多少錢,步驟如下:
-Count
方法一:下載完整帳本(Blockchain)後自己從裡面去找
方法二:向Peer公開Wallet的所有訊息,Peer就回傳屬於該Wallet的UTXO
方法三:向Peer公開Wallet的部份訊息,Peer回傳可能屬於該Wallet的UTXO
三種方法,各有優缺點。本篇介紹第三種,參考自,BIP37 - Connection Bloom Filtering。想深入了解Bloom Filter在Bitcoin Protocol的運作原理,建議多花一些時間閱讀。看得懂的,本篇文章就不用再看下去了。若看不太懂,希望本文對大家會有一些幫助,當然,最重要的一點是,鼓勵大家對照原來的BIP37,質疑本文的正確性,這樣做,有助於提升大家的思考能力。
用下圖說明,Wallet如何用Bloom Filter,去向Peer問,自己擁有多少錢。這裡,我們的前提條件是,Wallet被重啟後,只剩下Private Key,其它什麼都沒有。不用擔心,透過下面步驟,可以把錢找回來。

Wallet向Peer詢問,自己應該有多少錢,步驟如下:
- Wallet從Private Key推衍Public Key,再來是一組Address (a1, a2, a3)。最後建立Bloom Filter。可以想像它是一個過瀘器,用來過瀘大部份不屬於Wallet的Transaction。
- Wallet對Peer發送filterload message,將Bloom Filter傳給Peer。
- Wallet發送getblocks message,要求Peer傳回Block。若Wallet沒有發filterload,那麼Peer會準備一股腦的Block。但因為現在Peer有了Bloom Filter,所以它會過瀘大部份不相干的Transaction。
- 這時Peer開始從Blockchain中,用Bloom Filter找出可能屬於Wallet的Transaction,及其所屬的Block。假設第一個找到的是Block1,底下掛了一個tx1,其output指向a1,表示該transaction屬於Wallet。
- 為了要確保tx1的output沒有被花費到,Peer必須檢查是否有其它的transaction的input花費了a1。假設Peer發現了Block1底下掛了一個tx2,其input指向a1,就表示tx2花費了tx1的output。
- 若在Step 5發現Transaction有被花費,則Peer會依據Transaction的格式,及當初從filterload設定的Flag,決定要不要更新Bloom Filter。這樣會造成Bloom Filter的孔會愈來愈大,導致判定Transaction屬於Wallet的準確率也會變大。其中的細節,留待下一篇文章說明吧!
- 當Peer找到所有可能的Transaction後,就會發一個inv message,給Wallet。inv裡面會有:待選Transaction所屬Block的頭、Merkle Path、以及Transaction本身。
- 最後,Wallet收到inv message帶來的東西後。就依照中本聰論文理所提的兩種檢查方式:Merkle Path Proof和Proof of Work(這一點我以後再解釋),檢查那些Transaction是屬於Wallet,並且是尚未被花費的Transaction,然後建立UTXO Pool,暫時存放尚未被花費的屬於該Wallet的Transaction。將這些Transaction的Output加總,就是該Wallet的餘額(Balance)了。
本文遺留幾個問題,近期之內會說明:
- Peer在什麼情況下,會去更新Bloom Filter?
- 如何從,中本總Bitcoin P2P Network論文,解釋SPV檢查Transaction的方法?
至於Merkle Tree和Bloom Filter的原理,建議大家自己上網找資料,沒必要我就不多解釋了。
如何知道Bitcoin Wallet有多少錢?
Bitcoin Network,大致上有兩種Node:
如果只有Full Node,那我們就不用去想設計Merkle Tree,以及後來的Bloom Filter,那麼這個世界就簡單多了。但為了要讓Bitcoin Wallet(錢包)可以通行所有裝置,特別是手機,SPV Node就很重要了,不然就需要100G以上空間存放整個Blockchain,這是不可行的。
自從中本聰的Bitcoin P2P Network論文,2008年橫空出世之來,他就預測到,將來必定是SPV Node盛行,所以他很早就提出了SPV (Simplified Payment Verification)的概念。
而後來2012年提出的BIP37 - Connection Bloom Filtering,是基於SPV的概念,用Bloom Filter,提出一個更加可行的方案出來。
本篇先為這個問題:「Bitcion Wallet如何知道有多少UTXO?」,提供簡單的回答。
我們知道,Wallet只存所有的Block Header,而沒有全部的Transaction,最多只存屬於自己的Transaction。一開始,連Block Header都沒有的情況下,如何知道Wallet有些UTXO(Unspent Transaction Output)呢?它要去問具有完整帳本(Blockchain)的Peer。問的方式有兩種:
方法一:下載完整帳本(Blockchain)後自己從裡面去找
方法二:向Peer公開Wallet的所有訊息,Peer就回傳屬於該Wallet的UTXO
方法三:向Peer公開Wallet的部份訊息,Peer回傳可能屬於該Wallet的UTXO
這個問題,講白一點,就是:「我想知道錢包有多少錢?」
要知道真實的錢包有多少錢,直接打開來數一下就行了。Bitcoin Wallet,是電子錢包,運行的時候,會顯示目前的餘額,斷電的時候,不需要保存餘額,因為下次重啟的時候,只要去問就好了。根據什麼來問?Wallet惟一需要存放的,是一組Private Keys,被安全存放在晶片裡,可能是Secure Element或Trust Zone。這一組Key是別人獲取不到的,甚至Wallet App自己也獲取不到。Wallet的安全晶片,可以從Private Key去推算出Public Key。這個Public Key可以視為Address。有時候Address是從Public Key被Hash兩次算得來的。
我們把Address視為銀行的帳號。所以別人要給我Bitcoin,我就要將Address給別人,請他將錢匯到這個帳號,就行了。
回到原來的問題「我想知道錢包有多少錢?」
方法一:下載完整帳本(Blockchain),然後自己從裡面去找
這種方法,最簡單,但耗費的網路頻寬最多,至要要傳輸100G以上的資料量。因為Wallet沒有向Peer表明,那些Address屬於Wallet,所以Peer當然不知道那些Address屬於Wallet。我們無法從Blockchain存放的Address,往回推導出是從那一個Wallet產生出來的。所以Peer只好將Blockchain一股腦傳給Wallet,讓Wallet自己去找。
優點:結果精確,保留隱私
缺點:浪費頻寬
方法二:向Peer公開Wallet的所有訊息,Peer就回傳屬於該Wallet的UTXO
Wallet向Peer公開所有的Address,可是這樣一來,就洩露隱私。Peer拿到Address,就回報屬於該Wallet的UTXO,及所屬的Block。根據中本聰的論文,此Block不會自帶所有的Transaction,而是Merkle Path。
方法三:向Peer公開Wallet的部份訊息,Peer回傳可能屬於該Wallet的UTXO
Wallet向Peer公開部份訊息,以Bloom Filter呈現。Peer拿到Bloom Filter,就回報「可能」屬於該Wallet的UTXO,及所屬的Block Header,及Merkle Path。因為Bloom Filter沒有直接呈現Address,所以保留了一點隱私。
但是Bloom Filter,的特性是:
優點:保留一定程度的隱私,簡省頻寬
缺點:結果不精確 (但可接受)
下一篇,對「方法三」,會有圖文並茂的說明。
-Count
- Full Node,存放所有Block和Transaction
- SPV Node,存放所有Block Header
自從中本聰的Bitcoin P2P Network論文,2008年橫空出世之來,他就預測到,將來必定是SPV Node盛行,所以他很早就提出了SPV (Simplified Payment Verification)的概念。
本篇先為這個問題:「Bitcion Wallet如何知道有多少UTXO?」,提供簡單的回答。
我們知道,Wallet只存所有的Block Header,而沒有全部的Transaction,最多只存屬於自己的Transaction。一開始,連Block Header都沒有的情況下,如何知道Wallet有些UTXO(Unspent Transaction Output)呢?它要去問具有完整帳本(Blockchain)的Peer。問的方式有兩種:
方法一:下載完整帳本(Blockchain)後自己從裡面去找
方法二:向Peer公開Wallet的所有訊息,Peer就回傳屬於該Wallet的UTXO
方法三:向Peer公開Wallet的部份訊息,Peer回傳可能屬於該Wallet的UTXO
這個問題,講白一點,就是:「我想知道錢包有多少錢?」
要知道真實的錢包有多少錢,直接打開來數一下就行了。Bitcoin Wallet,是電子錢包,運行的時候,會顯示目前的餘額,斷電的時候,不需要保存餘額,因為下次重啟的時候,只要去問就好了。根據什麼來問?Wallet惟一需要存放的,是一組Private Keys,被安全存放在晶片裡,可能是Secure Element或Trust Zone。這一組Key是別人獲取不到的,甚至Wallet App自己也獲取不到。Wallet的安全晶片,可以從Private Key去推算出Public Key。這個Public Key可以視為Address。有時候Address是從Public Key被Hash兩次算得來的。
我們把Address視為銀行的帳號。所以別人要給我Bitcoin,我就要將Address給別人,請他將錢匯到這個帳號,就行了。
回到原來的問題「我想知道錢包有多少錢?」
方法一:下載完整帳本(Blockchain),然後自己從裡面去找
這種方法,最簡單,但耗費的網路頻寬最多,至要要傳輸100G以上的資料量。因為Wallet沒有向Peer表明,那些Address屬於Wallet,所以Peer當然不知道那些Address屬於Wallet。我們無法從Blockchain存放的Address,往回推導出是從那一個Wallet產生出來的。所以Peer只好將Blockchain一股腦傳給Wallet,讓Wallet自己去找。
優點:結果精確,保留隱私
缺點:浪費頻寬
方法二:向Peer公開Wallet的所有訊息,Peer就回傳屬於該Wallet的UTXO
Wallet向Peer公開所有的Address,可是這樣一來,就洩露隱私。Peer拿到Address,就回報屬於該Wallet的UTXO,及所屬的Block。根據中本聰的論文,此Block不會自帶所有的Transaction,而是Merkle Path。
優點:結果精確,簡省頻寬
缺點:洩露隱私
缺點:洩露隱私
方法三:向Peer公開Wallet的部份訊息,Peer回傳可能屬於該Wallet的UTXO
Wallet向Peer公開部份訊息,以Bloom Filter呈現。Peer拿到Bloom Filter,就回報「可能」屬於該Wallet的UTXO,及所屬的Block Header,及Merkle Path。因為Bloom Filter沒有直接呈現Address,所以保留了一點隱私。
但是Bloom Filter,的特性是:
- 沒有從Bloom Filter過瀘出來的Transaction,「一定」不是屬於Wallet的
- 從Bloom Filter過瀘出來的Transaction,「應該」是屬於Wallet的
- 而且隨者Wallet的Transaction數量愈大,「應該」的準確性就愈低。
優點:保留一定程度的隱私,簡省頻寬
缺點:結果不精確 (但可接受)
下一篇,對「方法三」,會有圖文並茂的說明。
-Count
2017年3月10日 星期五
從Gartner技術成熟度曲線,預測Blockchain及其它關鍵技術未來的發展
最近看一本書「區塊鏈 重塑經濟與世界」,裡面提到,Gartner技術成熟度曲線。有些技術,經過高價狂跌後,若還能爬起來,那就表示該技術將要邁向成熟階段。
下圖是2015技術成熟度曲線,發現並沒有Blockchain,但有與其相關的Cryptocurrencies,與Cryptocurrency Exchange,處於下滑階段。

再看下圖,2016技術成熟度曲線。Cryptocurrencies,與Cryptocurrency Exchange不見了,但Blockchain出現了,而且是在爆衝階段。

其它有趣的技術,比如IoT,在2015年,位在最高點,但在2016年,就不見了。到是IoT Platform還在維持,並在2016年上升了一點。這說明了IoT要搞好,Platform是關鍵。
另外還有AI相關技術。發現Machine Learning,2015正從頂峰下滑,2016又愉愉回到頂峰。這說明Machine Learning非常火。Virtual Personal Assistants,2015年出現,2016年還活者,並且往上爬。
還有,2015年和2016年,Quantum Computing還活者,我認為,這玩意兒,遲早會顛覆整個網路安全架構。
最後,將這些技術依成熟度排在一起:
Quantum Computing ==> IoT Platform ==> Blockchain ==> Machine Learning
未來發展可能會:
-Count
下圖是2015技術成熟度曲線,發現並沒有Blockchain,但有與其相關的Cryptocurrencies,與Cryptocurrency Exchange,處於下滑階段。

再看下圖,2016技術成熟度曲線。Cryptocurrencies,與Cryptocurrency Exchange不見了,但Blockchain出現了,而且是在爆衝階段。

其它有趣的技術,比如IoT,在2015年,位在最高點,但在2016年,就不見了。到是IoT Platform還在維持,並在2016年上升了一點。這說明了IoT要搞好,Platform是關鍵。
另外還有AI相關技術。發現Machine Learning,2015正從頂峰下滑,2016又愉愉回到頂峰。這說明Machine Learning非常火。Virtual Personal Assistants,2015年出現,2016年還活者,並且往上爬。
還有,2015年和2016年,Quantum Computing還活者,我認為,這玩意兒,遲早會顛覆整個網路安全架構。
最後,將這些技術依成熟度排在一起:
Quantum Computing ==> IoT Platform ==> Blockchain ==> Machine Learning
未來發展可能會:
- Machine Learning會想採用Blockchain最為資料核心引擎,所以Blockchain可能會先搭上Machine Learning的順風車。
- IoT Platform,先天上,就適合分散式的架構。所以當Blockchain技術成熟時,IoT Platform應該會想採用Blockchain技術。
- 後面就會跟來Quantum Computing,會將之前風行的技術重新洗牌。
-Count
2017年3月9日 星期四
為何傳統藍牙配對容易遭受攻擊?
傳統藍牙配對(Bluetooth Legacy Paring),最為人垢病之處,是容易遭受駭客攻擊。
其實原理很簡單,大家只要有時間,翻一下Bluetooth Spec,了解一些各種Key的產生方式,就知道如何進行攻擊。當然,這方面的文章,網路上很多,大家可以去看看。在這裡,用我自己的方式,解釋給大家。如果看完後,晃然大悟,那就是對大家有貢獻。若看完了還是不懂,可能是本人表達的不清楚,只好自己想辦法吧。
藍芽配對的流程,從輸入PIN產生Kinit,再產生Kab,即完成配對。配對完的兩個設備,都存放相同的Kab。用下面兩張圖(來自於Multilevel Security Algorithm for Bluetooth Technology)說明。


兩個設備靠近時,要建立安全通訊之前,要先確認對方設備是否曾經被配對過,也就是確認對方是否可信的(Trusted)。如下圖,Device A想要驗證Device B是否可信:

其實原理很簡單,大家只要有時間,翻一下Bluetooth Spec,了解一些各種Key的產生方式,就知道如何進行攻擊。當然,這方面的文章,網路上很多,大家可以去看看。在這裡,用我自己的方式,解釋給大家。如果看完後,晃然大悟,那就是對大家有貢獻。若看完了還是不懂,可能是本人表達的不清楚,只好自己想辦法吧。
藍芽配對的流程,從輸入PIN產生Kinit,再產生Kab,即完成配對。配對完的兩個設備,都存放相同的Kab。用下面兩張圖(來自於Multilevel Security Algorithm for Bluetooth Technology)說明。
兩個設備靠近時,要建立安全通訊之前,要先確認對方設備是否曾經被配對過,也就是確認對方是否可信的(Trusted)。如下圖,Device A想要驗證Device B是否可信:
- Device A發一個亂數AU_RANDa給Device B。
- Device B拿到AU_RANDa,和BD_ADDRa和Kab,計算,得到AU_RANDa。
- Device B回傳SRESa'給Device A
- Device A自已也會根據AU_RANDa用和Device B同樣的方式(E1),算出SRESa。
- Device A比較這兩個值,SRESa與SRESa',若一樣,表示Device B是可信的。
以上是兩個設備的驗證過程。駭客可以利用這一點,暴力破解,去猜PIN。若SRESa與RRESa'值一樣,表示PIN被猜到了。
我將上面3張圖,簡化成下面這張圖,就可以很清楚知道駭客會怎麼做了。


使用者,在做傳統藍牙配對的時候,駭客會用藍牙分析儀去監聽藍牙封包。分析儀是得不到PIN,因為那是使用者自己輸入的。但分析儀可以得到
- IN_RAND
- Kinit xor LK_RANDa
- Kinit xor LK_RANDb
- 雙方的藍牙位址:BD_ADDRa、BD_ADDRb
分析儀這些這值記錄下來,就可以對6位數字的PIN進行暴力破解了。通常,功能強大的藍牙分析儀,再抓封包的時候,會順便破解一下PIN。這種分析儀,我以Attacker稱之,如下圖:


攻擊步驟:
- Attacker監聽兩個設備配對的過程,截取以下值及藍牙地址,記錄在Table裡
- IN_RAND
- LK_RANDa xor Kinit
- LK_RANDb xor Kinit
- Attacker不知道Device的PIN,但知道配對時傳遞的一些數據,而且存在Table裡,於是開始爆力破解PIN。
- Attacker 發AU_RANDa給Device
- Device傳SRESA’給Attacker
- Attacker不斷地試PIN,就會一直產生SRESa。直到找到PIN,使得SERSa=SERSa’。因為PIN只有6位數,所以很快可以找到。
- 一旦Attacker知道PIN,就可以算出Kinit ==> Kab ==> Kc ==> Kc’。
- 之後兩個設備之間通訊是拿Kc’加密。因所以Attacker會順便破解藍牙通訊傳遞的密文。
為何Bluetooth Simple Paring無法採用這種方式?因為配對過程用的是ECC,雙方各有Public Key與Private Key,而且Key的大小是256 bit,很難爆力破解。這涉及到密碼學,以後有空再為大家介紹。
-Count
2017年3月7日 星期二
SPV Node如何建立UTXO Pool?
SPV Node如何建立UTXO Pool?
這個問題,又衍生另一個問題。
SPV Node需要建立包含所有UTXO的UTXO Pool嗎?
我們可以從Wallet(電子錢包)的角度去想這些問題。
Bitcoin的UTXO (Unspent Transaction Output),就是尚未花費的輸出,相當於現實世界還沒有花出去的鈔票。
Software Wallet是SPV Node的一種,它會有一個Database儲存屬於該Wallet的UTXO Pool。
Wallet為何不存放別人的UTXO呢?
因為這樣做沒有多大用處。我們知道Wallet,相當於現實世界的錢包,Wallet所記錄的UTXO,其值的加總,就相當於現實世界的錢包裡放了多少錢。
現實世界裡,你的錢包會記錄別人的錢包有多少錢嗎?
不會的。所以Bitcoin Wallet只記錄所屬的UTXO就好了。
使用新的Wallet,它的UTXO Pool為空的,因為還沒有用它來進行Transaction。只要有Transaction發生,並且該Transaction收集到Block,成為Blockchain,該Transaction的Output就是UTXO了。這時Wallet的UTXO Pool就會記錄一筆UTXO了。
UTXO Pool就是Persistent Database,如果被破壞了,UTXO不見了,是否表示錢就不見了?
我們使用Bitcoin不用擔心Database消失這件事。因為Wallet的UTXO來自於Blockchain,而每一個Node都有相同的Blockchain。所以UTXO不見了,只要去連網,重新下載UTXO就好了。我們要擔心的是Private Key消失或洩露。
即然Wallet的UTXO來自於網路上的Blockchain,為何還要自己保存一份在UTXO Pool?
那是為了Offline Payment方便。可以在離線狀況,知道自己有多少錢。甚至可以做到離線支付。
如何預防 Malicious Wallet (惡意錢包)?
Bitcoin Wallet有很多型式,程式是其中一種。我們可以自己寫一個Wallet程式,然後建立一個Transaction,去挖別人的UTXO,變成自己的嗎?
如果有別人的Private Key,這麼做是可行的,因為我們可以拿別人的Private Key對Transaction的Input簽名。這樣一來,當Transaction上傳到某個Node,會被驗證通過,進而放到Blockchain,這樣錢就要不回來了。
所以Wallet的Private Key非常重要,絕不能洩露出去,也絕不能不遺失。因為若Private Key遺失,我們就沒辦將UTXO花掉。所以:
所以有另一種Wallet叫Paper Wallet,就是將Private Key印出來,長的像鈔票似的,上面有Private Key,還有它的二維碼。說它長的像鈔票,其實就是鈔票。和一般鈔票不同,這張鈔票是不能給別人看到的,自己留者備份,防止Private Key遺失。
下圖是「Mastering Bitcoin」這本書裡,談到的Paper Wallet

Paper Wallet安全嗎?
這裡有一個吊詭的地方。我們做Security System的都知道,存放Private Key最安全的地方是Secure Element,程式是無法讀取裡面的Private Key。
-Count
這個問題,又衍生另一個問題。
SPV Node需要建立包含所有UTXO的UTXO Pool嗎?
我們可以從Wallet(電子錢包)的角度去想這些問題。
Bitcoin的UTXO (Unspent Transaction Output),就是尚未花費的輸出,相當於現實世界還沒有花出去的鈔票。
Software Wallet是SPV Node的一種,它會有一個Database儲存屬於該Wallet的UTXO Pool。
Wallet為何不存放別人的UTXO呢?
因為這樣做沒有多大用處。我們知道Wallet,相當於現實世界的錢包,Wallet所記錄的UTXO,其值的加總,就相當於現實世界的錢包裡放了多少錢。
現實世界裡,你的錢包會記錄別人的錢包有多少錢嗎?
不會的。所以Bitcoin Wallet只記錄所屬的UTXO就好了。
使用新的Wallet,它的UTXO Pool為空的,因為還沒有用它來進行Transaction。只要有Transaction發生,並且該Transaction收集到Block,成為Blockchain,該Transaction的Output就是UTXO了。這時Wallet的UTXO Pool就會記錄一筆UTXO了。
UTXO Pool就是Persistent Database,如果被破壞了,UTXO不見了,是否表示錢就不見了?
我們使用Bitcoin不用擔心Database消失這件事。因為Wallet的UTXO來自於Blockchain,而每一個Node都有相同的Blockchain。所以UTXO不見了,只要去連網,重新下載UTXO就好了。我們要擔心的是Private Key消失或洩露。
即然Wallet的UTXO來自於網路上的Blockchain,為何還要自己保存一份在UTXO Pool?
那是為了Offline Payment方便。可以在離線狀況,知道自己有多少錢。甚至可以做到離線支付。
如何預防 Malicious Wallet (惡意錢包)?
Bitcoin Wallet有很多型式,程式是其中一種。我們可以自己寫一個Wallet程式,然後建立一個Transaction,去挖別人的UTXO,變成自己的嗎?
如果有別人的Private Key,這麼做是可行的,因為我們可以拿別人的Private Key對Transaction的Input簽名。這樣一來,當Transaction上傳到某個Node,會被驗證通過,進而放到Blockchain,這樣錢就要不回來了。
所以Wallet的Private Key非常重要,絕不能洩露出去,也絕不能不遺失。因為若Private Key遺失,我們就沒辦將UTXO花掉。所以:
- 「Private Key遺失」,就是錢不見的意思。
- 「Private Key洩露」,就是錢隨時會被愉走的意思。
所以有另一種Wallet叫Paper Wallet,就是將Private Key印出來,長的像鈔票似的,上面有Private Key,還有它的二維碼。說它長的像鈔票,其實就是鈔票。和一般鈔票不同,這張鈔票是不能給別人看到的,自己留者備份,防止Private Key遺失。
下圖是「Mastering Bitcoin」這本書裡,談到的Paper Wallet
Paper Wallet安全嗎?
這裡有一個吊詭的地方。我們做Security System的都知道,存放Private Key最安全的地方是Secure Element,程式是無法讀取裡面的Private Key。
- 程式要能讀取Private Key,才能列印。
- 若Private Key能被程式讀取,表示它的儲存方式是不安全的。
-Count
誰決定比特幣的交易稅(Transaction Fee)?
比特幣的每筆Transaction,有時會出現Fee。是誰指定的?指定後對於Transaction會有何影響?
翻了一下「Mastering Bitcoin」這本書,總結如下:
翻了一下「Mastering Bitcoin」這本書,總結如下:
- Minimum Transaction Fee由市場決定 (市場如何決定?待下一篇說明之)
- Current Minimum Transaction Fee = 0.0001 bitcoin per kilobyte
- 建立Transaction的人,可以指定Fee,也可以不指定
- 若指定,至少要給Minimum Transaction Fee
- 可以多給Fee,這樣Miner若挖到包含該Transaction的Block,就賺到了
- 有些Miner喜歡挖有Fee的礦,有些不喜歡
- Age和Fee會影響Node要先處理那些Transaction
下圖,Block包含了二大塊:Block Header、Transaction Space。
Transaction Space又分二區,第1區存放High-Priority Transactions,第2區存放有Fee的Transactions。


每個Miner在挖礦之前,會建立一個Candidate Block(如上圖),並且從Transaction Pool裡挑選幾個Transaction塞進來。
首先會挑選High-Priority Transactions到第一區。如何判定Transaction是High-Priority?
先計算Transaction的Priority:
Priority = Sum (Value of Input * Input Age) / Transaction Size
若Priority > 57,600,000為High Priority,書中舉的例子如下:
有一個Transaction,Size為250 bytes,Input總計為1 Bitcoin = 100m satoshis,待了1天,經過144個Block,都沒有被處理到,它的Priority目前為57,600,000。所以只要再經過1個block,就有可能被下一個block處理到了。
High Priority > 100,000,000 satoshis * 144 blocks / 250 bytes = 57,600,000
接下來,根據Fee挑選Transactions會被塞到第2區。沒有Fee的Transaction,絕不會到第2區。沒有Fee的Transaction,要等到Age增加,成為High-Priority Transaction,才有機會被塞到之後的Block的第1區。
-Count
2017年3月4日 星期六
Bitcoin有那些Pool?
在讀完"Mastering Bitcoin"這本書之後,我發現Bitcoin Network裡有許多不同種類的Pool:
- UTXO Pool
- Pool of Address
- Vanity Pool
- Transaction Pool
- Orphan Transaction Pool
- Orphan Block Pool
- Mining Pool
- Managed Pool
如果我們無法很清楚地了解這些Pool的含義及差異,表示我們對於Bitcoin Network的認知還不夠。因此,這裡試圖為大家介紹這些Pool。但不能保證大家可以因此而了解整個Bitcoin Network的運作。大家還是要下功夫去學習,求學問,很少能一步登天。大家要不斷地:思考、思考、再思考……。
首先,我們來了解UTXO Pool
UTXO全名是Unspent Transaction Outputs,意思就是尚未花費的Bitcoin。將所有UTXO的值加起來,就是整個Bitcoin的市值。Bitcoin Client會有一個Persistent Storage記錄UTXO Pool。
Transaction Pool v.s. Orphan Transaction Pool
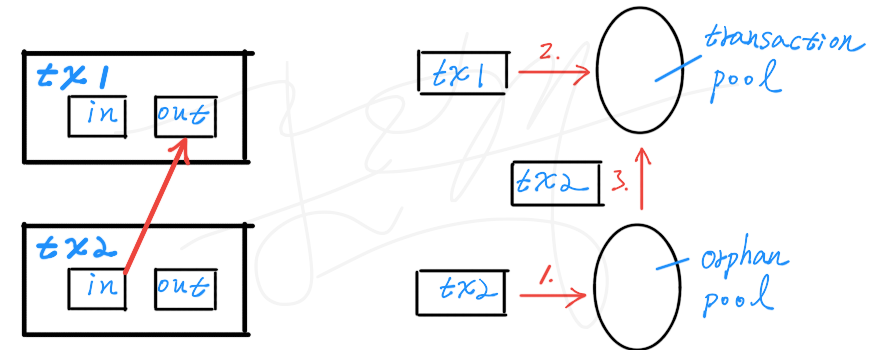
每次新產生的Transaction,被Node驗證後,會先存放在Transaction Pool。Transaction的每一個Input,都要指向一個Parent Transaction。但如果有兩個Transaction,tx1與tx2同時產生, tx1是tx2的父親,如下圖左所示。

(1) 若tx2先進入某一個Node,驗證後,發現tx2的父親還沒進來,那麼,該Node會將它視為孤兒(Orphan),於是就將它放到Orphan Transaction Pool。 (2) 直到tx1進來後,(3) Node找到了tx2的父親,就將tx2從Orphan Transaction Pool移到Transaction Pool。
(最後一段,有誤,己更正。感謝大學同學,益修指正)
總結:

存放在UTXO Pool的Transaction都是被驗證過的(Confirmed),並且是以Persistent Storage形式永久存放的。
存放在Transaction Pool或Orphan Pool是尚未被驗證過的(Unconfirmed),是暫時存在Memory裡。
至於其它Pool,留待下篇講解。
-Count
UTXO全名是Unspent Transaction Outputs,意思就是尚未花費的Bitcoin。將所有UTXO的值加起來,就是整個Bitcoin的市值。Bitcoin Client會有一個Persistent Storage記錄UTXO Pool。
Transaction Pool v.s. Orphan Transaction Pool
每次新產生的Transaction,被Node驗證後,會先存放在Transaction Pool。Transaction的每一個Input,都要指向一個Parent Transaction。但如果有兩個Transaction,tx1與tx2同時產生, tx1是tx2的父親,如下圖左所示。
(最後一段,有誤,己更正。感謝大學同學,益修指正)
總結:
存放在UTXO Pool的Transaction都是被驗證過的(Confirmed),並且是以Persistent Storage形式永久存放的。
存放在Transaction Pool或Orphan Pool是尚未被驗證過的(Unconfirmed),是暫時存在Memory裡。
至於其它Pool,留待下篇講解。
-Count
2017年3月3日 星期五
訂閱:
意見 (Atom)