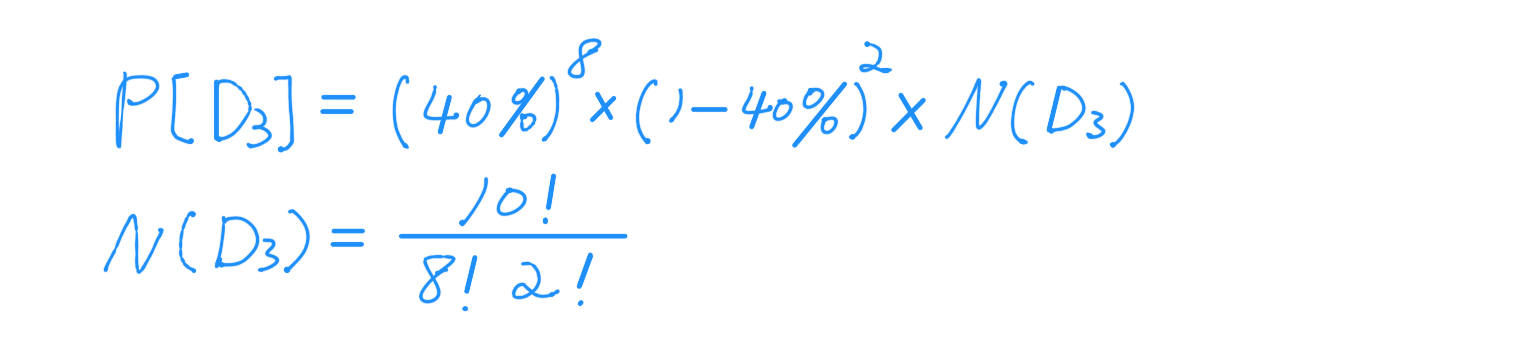本篇主要的目的是總結Machine Learning Foundations教材。在教材的迷宮中,我把目光拉遠一點,看看到底機器學習的目的是什麼?為何機器學習需要用到統計學的觀念?
機器學習,簡單一句話,就是從已知的,找到一個合適的假設hypothesis,用它來預測未知的。而在統計學裡,樣本是已知的,母體是未知,所以機器學習攀上了統計學的原因在此。
機器學習的過程,是從許多hypothesis裡,挑出最好的。在這過程中,會遇到三個主要問題:
- 如何檢驗hypothesis?
- 如何挑選hypothesis?
- 檢驗挑選hypothesis都在樣本裡做,為何能代表在母體裡檢驗挑選hypothesis?
1. 如何檢驗某個hypothesis?
我們只能從已知的樣本資料,去驗證某個hypothesis。已知的樣本資料如下:

D = Sample
|D| = N
1 <= n <= N
樣本資料有一個特性,就是對所有xn而言 yn = f (xn)。但我們不知道f長什麼樣子。我們只能想辦法去推測它。所以找到一個hypothesis,h。用樣本資料去檢驗h。檢驗方式如下:

這就用樣本檢驗h的方法。若發生錯誤的次數愈少,就是好的h。
2. 如何挑選hypothesis?
我們可以設計一套演算法,如PLA,每次找到的hypothesis,發生錯誤的機率愈來愈少。之前發表PLA相關文章:
解釋 PLA 演算法
PLA 中 sign (w * x) 的幾何意義
Why PLA May Work - Step 1
Why PLA May Work - Step 2
解釋 PLA 演算法
PLA 中 sign (w * x) 的幾何意義
Why PLA May Work - Step 1
Why PLA May Work - Step 2
3.為何從樣本裡挑選hypothesis的過程,可相當程度代表從母體挑選hypothesis
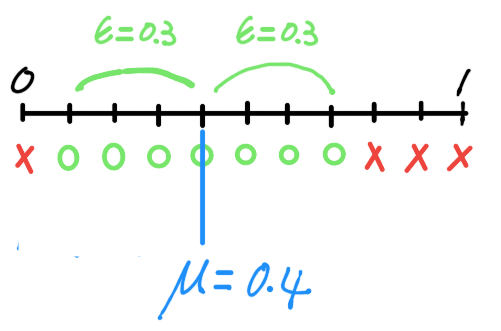
對一個hypothesis,h而言,只要樣本資料夠大,用樣本檢驗h,發生錯誤的機率,相當於用母體檢驗h,發生錯誤的機率。這個現象,可以用Hoeffding's Inequality解釋。我在之前的幾篇文章有提過:
Explain Hoeffding's Inequality with Python
Hoeffding's Inequality & Machine Learning
上面這句話,用數學式子表達如下:
Explain Hoeffding's Inequality with Python
Hoeffding's Inequality & Machine Learning
上面這句話,用數學式子表達如下:
用樣本檢驗h,發生錯誤的機率:

用母體檢驗h,發生錯誤的機率:

樣本資料夠大,這兩個錯誤的機率會非常接近,因為遵循Hoeffding's Inequality:

對於某個h而言,定義BAD Data如下:

有了BAD Data的定義之後,就可以將上面的Hoeffding's Inequality,簡化為以下這個式子:

用下面表格,會比較好理解這個式子:

D1, D2, … D5678, … 為將所有可能的樣本列舉出來。所以:
|D1| = |D2| = … = |D5678| = N
N = 樣本資料的數量。
簡單來講就是,若是樣本數量夠大,那麼發生BAD Data的機率就愈少,這是因為Hoeffding Inequality。
在只有一個hypothesis的情況下,只要樣本數量夠大,那麼樣本檢驗h的結果,相當於用母體檢驗的結果。問題是,機器學習的過程,會用到好幾個hypothesis,用樣本檢驗這些hypothesis的結果,是否就相當於用母體檢驗這些hypothesis的結果?我們希望的答案是YES,不然,機器學習是沒有用的。在Machine Learning Foundations教材裡,有答案YES的推導過程。教材裡用下面表格視覺化此問題:

總共有M個hypothesis。用樣本與母體檢驗這M個hypothesis,發生BAD Data的機率為:

Case 1 - M為無限大
Case 2 - M愈大
- 如此一來,機器學習就不用談了,因為從樣本學到的東西,無法套用在母體,永遠學不會
Case 2 - M愈大
- 好處:更多的hypothesis,容易找到錯誤率最小的
- 壞處:發生BAD Data的機率愈大
- 好處:發生BAD Data的機率愈小
- 壞處:更少的hypothesis,難找到錯誤率最小的
Case 1是我們面對最大的問題。因為之前提到的PLA,若將每條直線視為hypothesis,會有無限多個hypothesis。所以我們要將無限的hypothesis,轉換為有限的dichotomy。這就是為何Machine Learning Foundations,會有很大的篇幅說明dichotomy的原因。也可以參考之前談過dichotomy的文章:
Definition of Dichotomy
Max Number of Dichotomies
至於Case 2和Case 3,在教材裡,就是Trade-off on M。以後有機會再為大家解釋。
Definition of Dichotomy
Max Number of Dichotomies
至於Case 2和Case 3,在教材裡,就是Trade-off on M。以後有機會再為大家解釋。
-Count